
Terminology
-
Metadata package – A collection of metadata components that are supported by the plugin.
-
Managed package – Packages owned and managed by Salesforce or Salesforce partners.
-
Unmanaged package – Packages that are created as part of customizations done by end users.
-
The plugin – The masking plugin for Salesforce Package Management.
-
Task – A step in the plugin execution.
Creating a masking job
-
To create a masking job, select the New Job button at the top of the Jobs page.
-
In the Connector section, select a connector to use as the source (and sometimes also the target) of a masking job.
-
The Synchronize schema option is recommended if the schema of the source has changed from the last time it was synchronized. This process can take several minutes and will prevent the next step of the masking job from being triggered until finished.
-
-
In the Ruleset section, choose any available Ruleset within Delphix Compliance Services, or start with an empty one by selecting Define custom rules.
-
Defining custom rules will make the Customize Rules checkbox a requirement. If using an existing Ruleset, the Customize Rules checkbox is optionally used to modify the ruleset for this specific job.
-
The ruleset selected in the previous section can be tuned specifically for the job being created; these changes will not be saved in the ruleset itself. If a given column/field from the database should not be masked, search for it and mark the algorithm as None.
-
-
-
In the Configuration section, masking table filters can be applied with the provided Salesforce Object Query Language (SOQL) WHERE clauses for any table in the job. For more information, please see the Custom filters on the masking page.
-
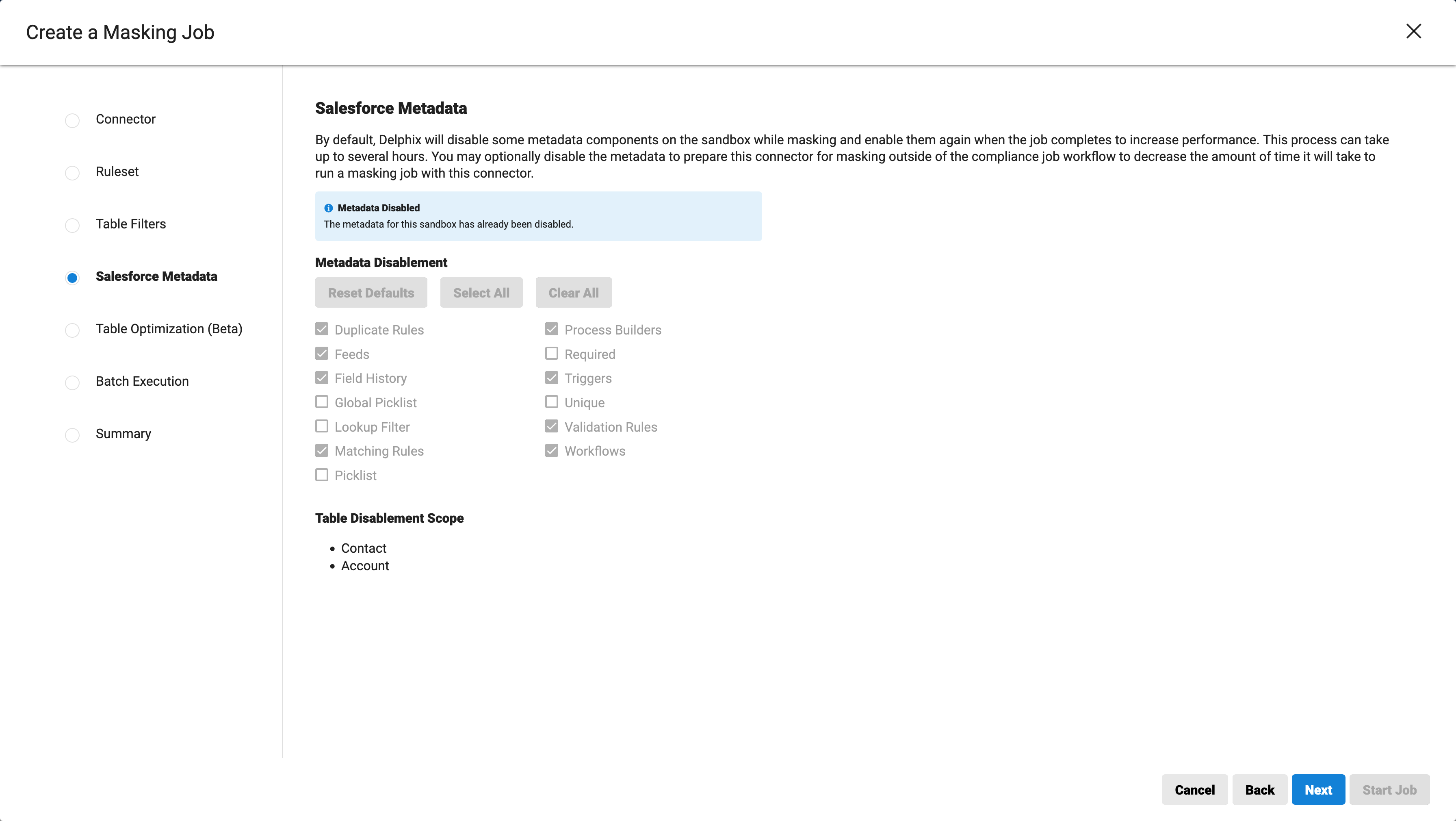
In the Salesforce Metadata section, users can select the exact metadata components to disable as well as what tables to disable. Please note that, if the metadata components are already disabled at the connector level, this option will be inactive.
-
This will allow the user to specify exactly which of the metadata components should be disabled as part of the masking job. The following list contains the metadata components:
-
Triggers
-
Workflows
-
Process Builders
-
Validation Rules
-
Feeds
-
Field History
-
DuplicateRules
-
Picklist
-
GlobalPicklist
-
Unique
-
MatchingRule
-
Required
-
LookupFilter
-
-
-
In the Table Optimization (Beta) section, select whether to use table optimizations.
-
This feature is useful if the tables to be masked are very large (in order of 10 million rows or more).
-
Opting into this feature will allow Delphix to use some fine-tuned performance controls, which will improve the overall query operation time for a very large table.
-
-
In the Batch Execution section, specify a batch execution mode and batch size.
-
Batch Mode – Select whether to run a bulk update in serial or parallel mode.
-
Parallel – By default, DCS reads, masks, and submits Salesforce asynchronous batch jobs serially. To achieve parallelization, DCS submits subsequent batches before previously submitted batches are complete or even started (queued). Running batch jobs in parallel may cause row lock issues, where multiple processes attempt to acquire a single lock. For example, the field
Full_namedepends on the fieldsFirst_nameandLast_name. If there is a batch job updating theFirst_nameorLast_nameof a row, theFull_namefield will be locked down. If another batch job wants to update theFull_namefield of the same row, a row lock issue may occur at this point. -
Serial mode – The
serialize_updatesattribute of the create job request payload is set to true. The parameter will then be added to the JDBC URL connection parameters that will be used by the CDATA’s JDBC Batch APIs.
-
-
Batch Size – Controls the batch size for updating values in Salesforce. It does not affect reading values from Salesforce. Select either Automatic, API Optimized or Custom batch size.
-
Automatic – DCS estimates the batch size on a table-by-table basis before masking begins. Automatic batch sizing performance is high but due to the exact sizes being unknown at the time of estimation, some cases with large data sizes may fail.
-
API Optimized – In this approach, each Salesforce bulk data-load job batch is dynamically loaded to its maximum capacity considering all the Bulk API limits specific to ingest jobs. Thus, the API calls are as few as possible. The system loads each batch until it hits limits and sends it to Salesforce. API optimized is the most reliable method but has a slower performance.
-
Custom – Applies a single, user-defined batch size across all tables in a dataset. Smaller batch sizes have a reduced risk of failure.
-
-
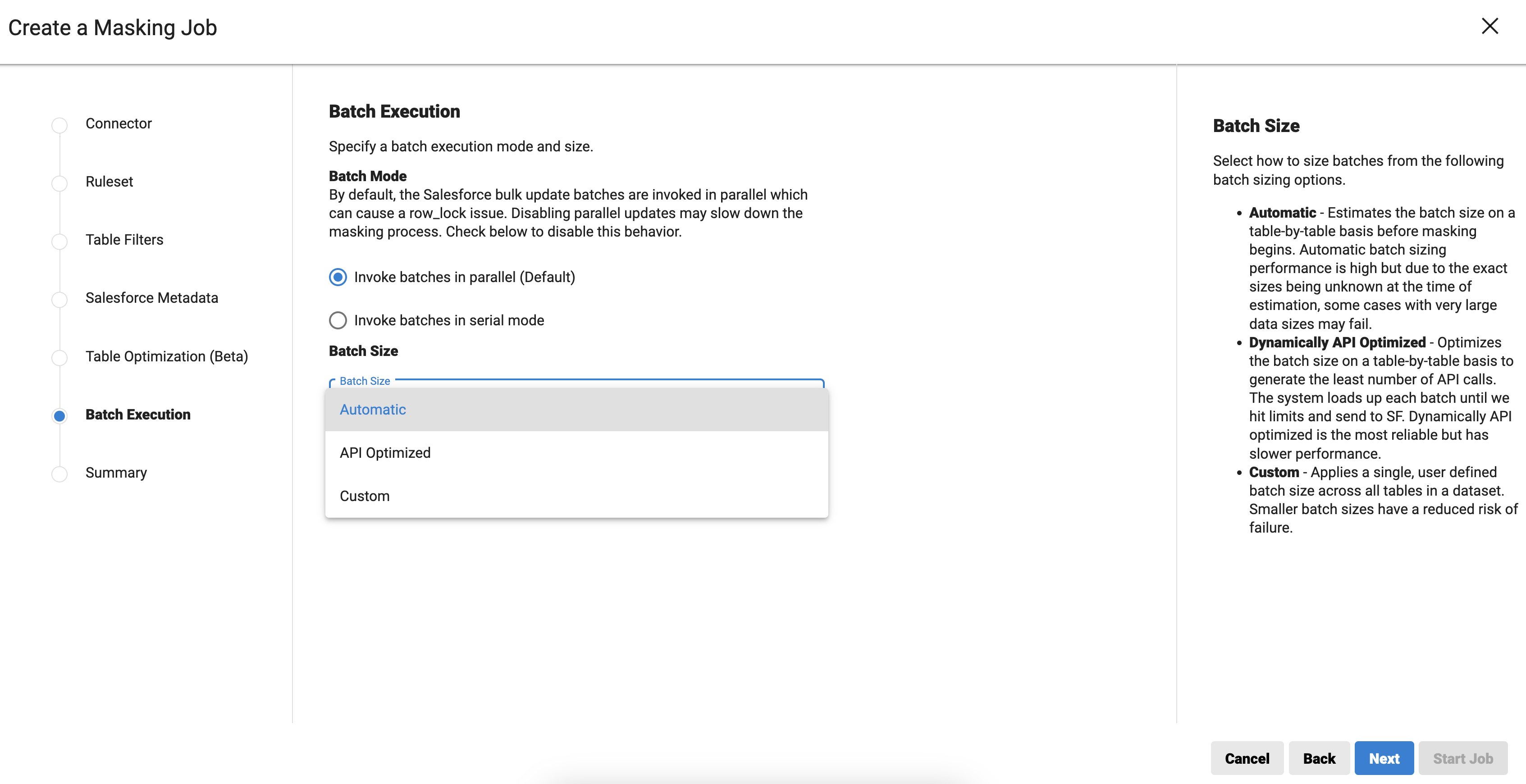
API-optimized option performs 10-15% slower than the Automatic option depending on various factors i.e. number of rows/columns in a table, data length of columns etc.
-
In the Summary section, review the details of the masking job configuration, then click Save.
Delphix does not recommend skipping disabling the triggers, as it could cause the masking job to run slow or prevent it from running at all.
Selecting components to disable will be inactive if the metadata components are already disabled at the connector level.
Job Table
Inside the drawer of each compliance job, the disabled metadata components, table optimizations, and masking filters applied are shown.
Job Executions
When a job is created it automatically applies a filter to the data in Salesforce such that only data that was last modified before the job began is to be masked. This is because jobs may have subsequent executions that are used to leverage the same connector and ruleset but continue masking where it left off. This means that it is essential to not edit any data in your Salesforce sandbox while any job execution is running.
If an execution was unable to completely mask the Salesforce sandbox due to either an abortive or a non-abortive error, under some conditions it can be resumed. Namely, if the job is less than one week old, and is not in a state that prevents it from being resumed. In these scenarios, each subsequent execution will apply the same filter as the original job (i.e. mask data that was modified before the job was created), as well as an additional filter to filter out data that was modified during the run of the previous executions – but that may have been manually edited by a Salesforce user outside of the context of the job (i.e. if the previous execution ended at time T, also include data that was updated after time T).
You can view the execution history from the Job Details page. Each execution also has additional details and has its own associated masking report as well.
Plugin operation stages
Setup
In the setup stage, the Package Manager prepares the data necessary to perform its work. Specifically, the Package Manager performs the following:
-
Retrieve table names from the ruleset of the current masking job.
-
Perform
FlowDefinition,ApexTrigger, andCustomFieldprocessing for each table name.
Pre-task
In the pre-task stage, the Package Manager disables the metadata packages on the tables that are being masked by a masking job. This stage grooms the table(s) for data masking. Specifically, the Package Manager performs the following:
-
Perform Metadata Retrieval.
-
Perform Metadata Deploy without any modification, to check if the Metadata configuration retrieved from the Salesforce instance has any issues or not.
-
Perform XML modification to disable packages and then perform Metadata Deploy.
|
File Type |
Parent Node |
Node |
Value |
|---|---|---|---|
|
Triggers |
ApexTrigger |
status |
InActive |
|
Workflows |
rules |
active |
false |
|
Validation Rules |
validationRules |
active |
false |
|
Feed History |
fields |
trackFeedHistory |
false |
|
Field History |
fields |
trackHistory |
false |
|
Process Builders |
FlowDefinition |
activeVersionNumber |
0 |
Post-task
In the post-task stage, the Package Manager enables the metadata packages that were disabled in the pre-task stage. Specifically, the Package Manager performs the following:
-
Perform Metadata Deploy to enable Metadata packages that were disabled in Pre-Task.
-
Perform cleanup of the base working directory.
Disable rehearsal tool for all tables in the schema
Some automations become disabled by DCS while running masking jobs, then they are enabled again when the job completes. Triggers and validation rules on the sandbox are parts of the aforementioned automations that are disabled by default while masking.
An option is available where users can choose to disable triggers and validation rules on all tables in the sandbox, not only the masked tables. If desired, users can tell DCS not to disable triggers and validation rules by selecting the Do not disable triggers and validations option.
When users select either the Disable triggers and validations on all tables or the Disable triggers and validations only on masked tables option, the run_triggers attribute of the create job payload is set to true, and the target_trigger attribute is set to the selected value.
If users select Do not disable triggers and validations, the run_triggers attribute will be set as false.
Run a masking job in serialized mode
When running a masking job, DCS updates Salesforce records using Salesforce Bulk API V2, which is abstracted by CDATA's JDBC Batch APIs. Salesforce bulk jobs are leveraged to achieve parallelization in future DCS updates.
Bulk job and batch job
Many Salesforce batch jobs belong to one bulk job. A bulk job has a max size of 100,000 records and a batch job has a max size of 10,000 records. Within a batch job, Salesforce processes 200 records at a time (in a chunk), which also corresponds to a transaction.
API
When the create-job endpoint is called, the user can specify the metadata components to disable in the request payload, which will be included in the generated configuration file as it is passed to the masking container.