Overview
Custom filters provide a robust solution for masking Salesforce data. Their advantages include:
-
Efficiently masking vast tables (> 50 million rows)
-
Addressing masking errors without the need for reseeding
-
Allowing selective field masking based on specific criteria or filters
-
Allowing sorting on the table being masked based on the field(s) present in the table
Performance and filters
For optimal performance, construct custom filters on indexed fields. Salesforce automatically indexes the following fields:
-
Salesforce IDs
-
CreatedDate
-
Systemmodstamp (LastModifiedDate)
-
RecordTypeId
-
Division
-
Name
-
Email (specifically for contacts and leads)
-
Foreign key relationships (both lookups and master-detail)
It is also possible to designate custom fields as indexed fields.
Masking large tables
Handling large Salesforce objects (those with over 70 million records) can be intricate due to the challenges in querying and updating at such a scale. While it is feasible to mask these large tables all at once, it is not advised. Instead, it is best to mask incrementally in smaller subsets to prevent timeouts and errors.
For this segmentation:
-
Choose filters that can evenly divide data. Indexed fields like IDs are suitable since they are typically evenly distributed.
-
Alternatively,
CreatedDatecan be used. However, this might introduce data imbalance because of activities like data migrations that could cluster many records within a short timeframe.
For instance, using IDs, different masking tasks can be initiated for specific subsets. The subsets might be defined by ID ranges, with 01Z4X000001ABhjAAA being the highest ID in the first subset, and 01Z4X000001ABhjFFF being the last ID in the second. Each subset should ideally contain 50 million records or fewer.
|
Subset 1 |
Subset 2 |
Handling masking errors
Errors during masking can lead to partially masked data. Instead of reseeding everything, employ custom filters to mask only the records that were not processed correctly. The Salesforce Systemmodstamp field can be instrumental here, as it indicates the last update time for a record.
For example, if during a masking operation 5,178,284 fields are masked but 14,492 records face an integrity exception error, you can fix the issue in either the ruleset or Salesforce and run another masking job targeting only the problematic records.
If the Systemmodstamp of the initial masking job was set to 2018-03-30T00:00:00.000Z, you can create a filter to address only records updated before this time. This ensures that records already masked will not be processed again. Plus, since Salesforce indexes the Systemmodstamp field, performance is optimized when using custom filters based on it.
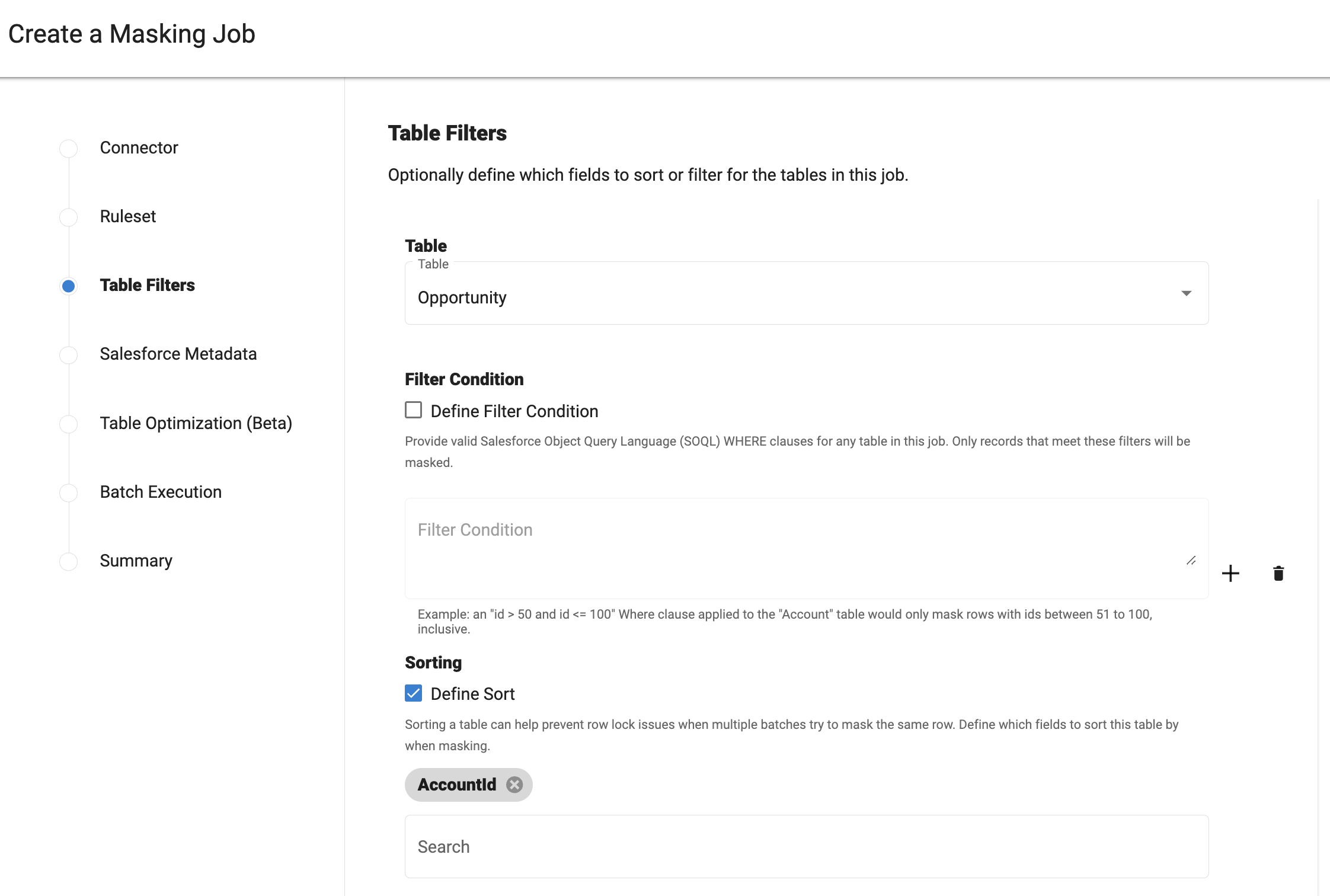
Handling ROW_LOCK batch failures
When executing a masking job with the default configuration and parallel batch processing, we sometimes encounter ROW_LOCK issues which lead to a large number of unmasked records.
This issue is seen when masking an object that has a child-parent relationship to another object. For example: When updating a record in a child object (such as Opportunity), the system attempts to acquire a lock on its parent object (such as Account) record. Therefore, if two batches are getting masked in parallel and referring to the same parent record, one of these batches fails to acquire the lock. Although Salesforce attempts to acquire the lock multiple times, after a certain number of attempts, it eventually gives up, resulting in a ROW_LOCK error for each failed record.
In such a situation, the ROW_LOCK errors can be significantly reduced, if not eliminated completely, by sorting the child table on the parent ID field. This would ensure that most records with the same parentID remain in the same batch. In the above mentioned example, we will apply the Sorting masking filter on the "AccountId" field in Opportunity table and then proceed to run the masking job.