
Importing templates
To import the latest version of all templates, follow these steps:
Templates are available in the following repository: https://github.com/delphix/dcs-for-azure-templates/tree/main
To import the required template into your data factory using the Data Factory Studio, perform the following steps:
Go to the Data Factory page and click on the Author tab (the pencil ✏️ icon on the left-hand side of the page).
In the Factory Resources section, click the "+" button next to the search bar.
Select 'Pipeline', then choose 'Import from pipeline template'.
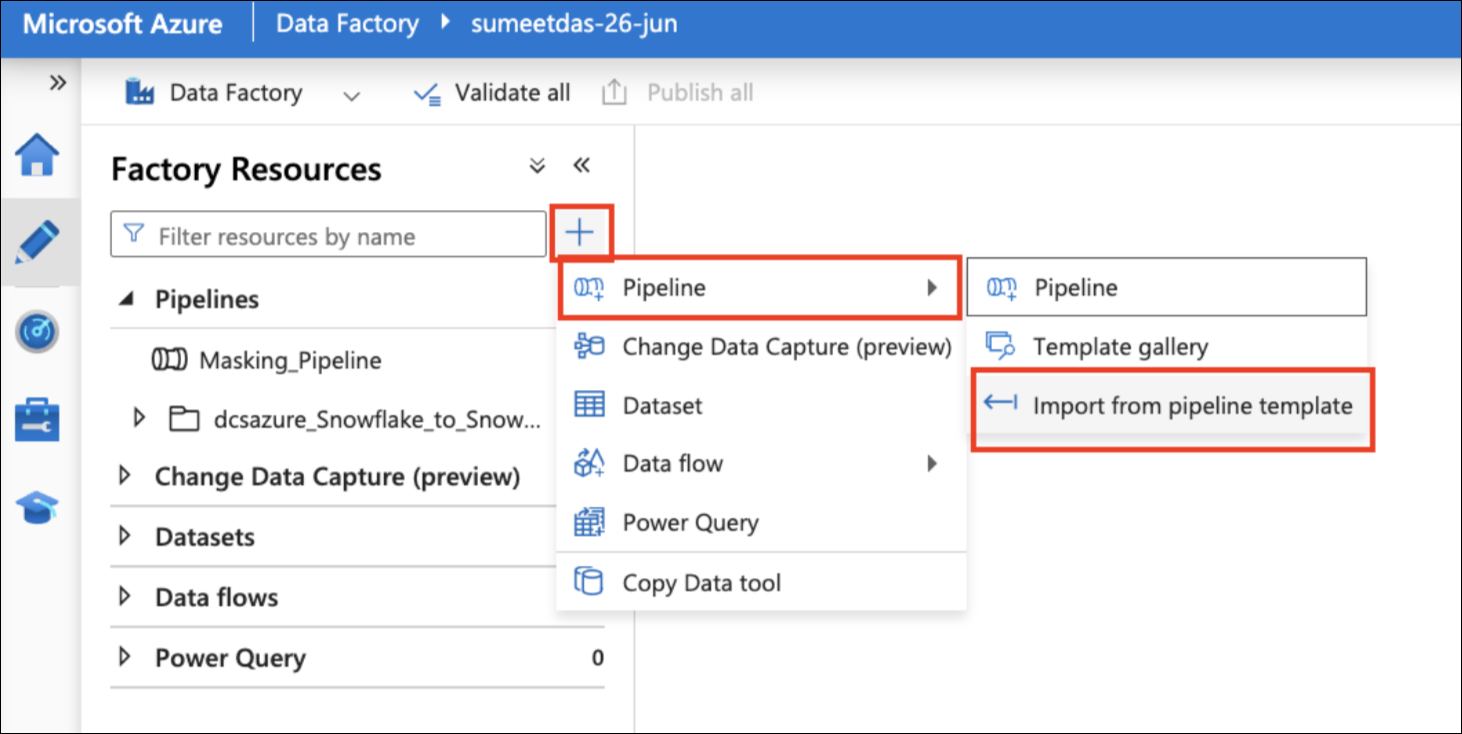
This will open a file explorer window. Select the required template from the releases folder. Each template has its own details explained in their respective sections. For this section, we will select the dcsazure_Snowflake_to_Snowflake_prof_pl.zip file. This zip file contains the profiling pipeline for automated sensitive data discovery on your Snowflake Instance.
After importing the zip file, the following page will be displayed.
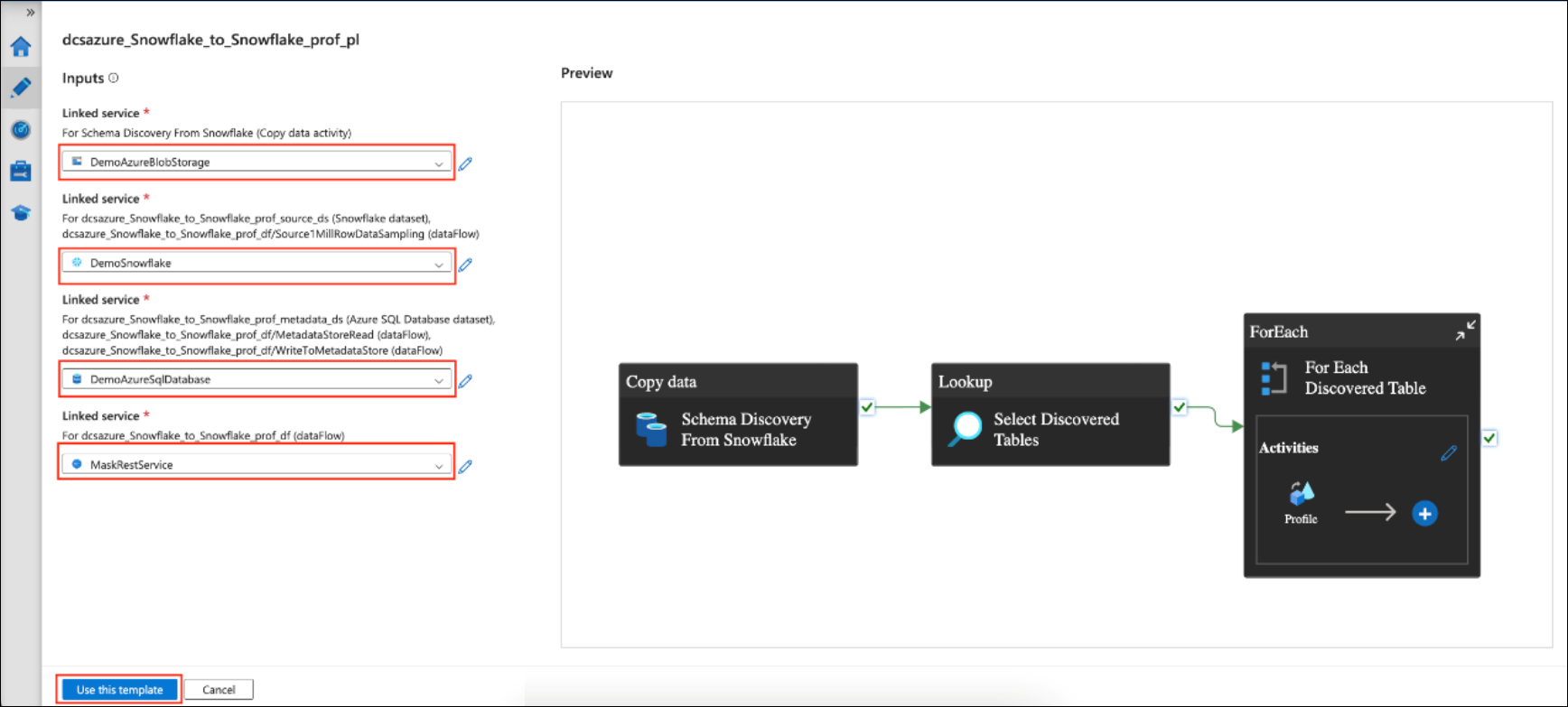
The above image shows an 'Inputs' section where you need to select linked services that will be used in various steps of the pipeline.
Inputs for each pipeline may vary. Details on the inputs and their prerequisites can be found in their respective pages. For example, for the Snowflake-to-Snowflake profiling pipeline, you can find the documentation here
For now, we have populated the inputs with the following linked services:
DemoAzureBlobStorage - linked service to Azure Blob Storage for storing staging data. This will be used for schema discovery from Snowflake during Copy Data activity.
DemoSnowflake - linked service to the Snowflake instance on which profiling will be performed.
DemoAzureSqlDatabase - Linked service to the Azure SQL DB that will be used as a metadata store
MaskRestService - Linked service to the DCS for Azure REST service.
Click on the "Use this template" button.
This will show the following page:
Change the name of the pipeline inside the 'Properties' section.
Click on the 'Validate All' button (found on the left side of the 'Publish all' button highlighted above) to check for any validation errors. If the linked services are configured correctly, there should be no validation errors. Note that any validation error will prevent you from publishing the pipeline.
Once validation is done, click on the 'Publish all' button to publish the pipeline.
The imported pipeline by default will use the AutoResolvingIntegration runtime for dataflows that are part of this pipeline. It is highly recommended that you update the integration runtime to your configured one.