
Best practices
This article outlines the Azure Data Factory ETL pipeline configurations and considerations. The general guideline is to start with a configuration that delivers reasonable performance and scale up to meet your performance needs.
Be mindful of your vCore availability with Azure, as scaling to larger compute sizes may result in failed pipeline runs if resource consumption reaches the quota limit.
SQL database
Adequate database compute size ensures consistent query latency and prevents query timeouts. Larger compute sizes also provide additional workers, database IO, and transaction log throughput. Select the SQL DB compute size that can satisfy the required storage, memory, CPU capacity, and transaction log throughput.
Single databases with no specific performance requirements can use the GP_S_Gen5_12 serverless instance with these characteristics:
Scaling from 1.25 to 12 vCores
4.5 to 36 GB of memory
Maximum storage amount of 3072 GB
For more details on SQL DB sizes and limits, visit this Azure documentation.
Integration Runtime (IR)
Integration Runtimes (IRs) are Spark clusters that execute data flows; running data flows in parallel will result in multiple running IRs, one for each data flow. Larger IRs will execute the data flow faster, since they can parallelize the operations across more Spark nodes.
A 16 (+16 Driver Cores) IR cluster size is recommended for reasonable performance. Scaling to larger sizes can improve masking performance and reduce execution time.
Memory-optimized compute IR can improve performance and minimize failures due to low memory conditions for larger databases, e.g. tables with 20 million rows and more than 10 masked columns.
Data flow
For SQL database, use Round Robin partitioning optimization for the source to get the best performance. The number of partitions should be the same as the number of worker nodes in the IR Spark cluster, e.g. 16 (+16 Driver Cores) IRs should use 16 partitions.
A data flow is created for each masking table, thus, multiple masking tables will each have a data flow. Data flows in a pipeline can be configured to execute sequentially, one data flow and one running IR at a time, or in parallel with multiple IRs executing data flows concurrently. Configure parallel execution to reduce execution time.
Disabling the time to live (TTL) setting in the Integration Runtime settings may help reduce cost. If sequential execution is preferred, enable TTL so subsequent jobs can reuse the existing cluster and reduce startup time.
Determining number of batches for ADF Aggregate settings
A batch is a number of rows in a masking request. Larger batches generally result in better performance since more rows would be processed for each API request. The masking endpoint enforces a maximum payload limit of 2MB. Determining the optimal (close to 2MB limit) batch size/the number of batches (Aggregate Group By setting) is important.
Factors such as the number of columns to be masked, the character length of the column identifiers, and the character length of the data to be masked, all affect how many rows you will be able to post in a single batch payload. Payloads that exceed the 2MB limit will result in HTTP status code 413: Request Entity Too Large.
The below table can be used as a starting point for determining an appropriate batch size.
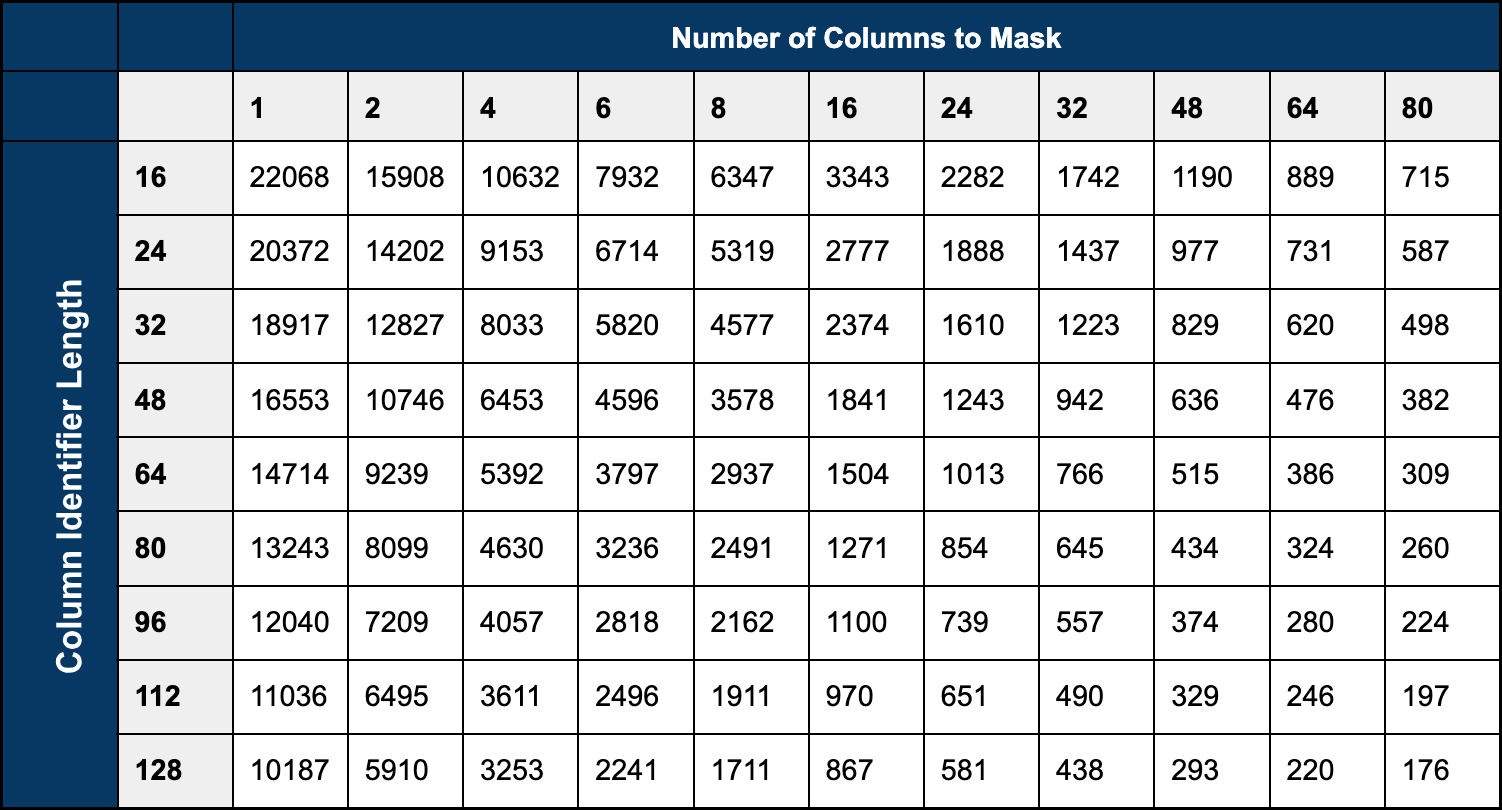
Example
There is a one million row table with four columns containing data to be masked, the longest column identifier of the four columns to mask is 14 characters. Looking at the table above, the closest value is (4/16); the batch size is approximately 10,632 rows (depending on the size of the data to be masked). Rounding down to 10,500 rows per batch, then taking the total row count (1,000,000) divided by the batch size (10,500), the result (95.24) is rounded up to the next whole number. The number of batches for this table in an ADF dataflow is 96.
If the dataflow fails due to 413 errors using the formula above, increase the number of batches (a smaller batch size) until a value is found that works for the dataset.